





Язык программирования: Delphi (Object Pascal)
Содержание
Вопрос 1. Введение в теорию структур данных и алгоритмов их обработки. Типы данных 1
Вопрос 2. Статические и полустатические структуры данных 6
Вопрос 3. Динамические структуры данных 22
Вопрос 4. Рекурсивные структуры данных 40
Вопрос 7. Преобразование ключей (расстановка) 76
Вопрос 1. Введение в теорию структур данных и алгоритмов их обработки. Типы данных.
В математике принято классифицировать переменные в соответствие с некоторыми важными характеристиками. Мы различаем вещественные, комплексные и логические переменные, переменные, представляющие собой отдельные значения, множества значений или множества множеств. В обработке данных понятие классификации играет такую же, если не большую роль. Мы будем придерживаться того принципа, что любая константа, переменная, выражение или функция относятся к некоторому типу.
Фактически тип характеризует множество значений, которые может принимать некоторая переменная или выражение и которые может формировать функция.
В большинстве языков программирования различают стандартные типы данных и типы, заданные пользователем. К стандартным относят 5 типов:
а) целый (INTEGER);
б) вещественный (REAL); в) логический (BOOLEAN); г) символьный (CHAR);
д) указательный (POINTER).
К пользовательским относят 2 типа:
а) перечисляемый;
б) диапазонный.
Любой тип данных должен быть охарактеризован областью значений и допустимыми операциями над этим типом данных.
-
Целый тип – INTEGER.
Этот тип включает некоторое подмножество целых, размер которого варьируется от машины к машине. Если для представления целых чисел в машине используется n разрядов, причем используется дополнительный код, то допустимые числа должны удовлетворять условию -2 n-1<= x< 2 n-1.
Считается, что все операции над данными этого типа выполняются точно и соответствуют обычным правилам арифметики. Если результат выходит за пределы представимого множества, то вычисления будут прерваны. Такое событие называется переполнением.
Числа делятся на знаковые и беззнаковые. Для каждого из них имеется свой диапазон значений:
а) (0…2n-1) для беззнаковых чисел; б) (-2N-1… 2N-1-1) для знаковых.

Рис. 1
При обработке машиной чисел, используется формат со знаком. Если же машинное слово используется для записи и обработки команд и указателей, то в этом случае используется формат без знака.
Операции над целым типом:
а) Сложение. б) Вычитание. в) Умножение.
г) Целочисленное деление.
д) Нахождение остатка по модулю.
е) Нахождение экстремума числа (минимума и максимума).
ж) Реляционные операции (операции сравнения) (<,>,<=, >=,=,<>). Примеры:
A div B = C A mod B = D C * B + D = A
7 div 3 = 2
7 mod 3 = 1
Во всех операциях, кроме реляционных, в результате получается целое число.
-
Вещественный тип – REAL.
Вещественные типы образуют ряд подмножеств вещественных чисел, которые представлены в машинных форматах с плавающей точкой. Числа в формате с плавающей точкой характеризуются целочисленными значениями мантиссы и порядка, которые определяют диапазон изменения и количество верных знаков в представлении чисел вещественного типа.
X = +/- M * q(+/-P) – полулогарифмическая форма представления числа, показана на рисунке 2.
937,56 = 93756 * 10-2 = 0,93756 * 103

Рис. 2
Удвоенная точность необходима для того, чтобы увеличить точность мантиссы.
-
Логический тип – BOOLEAN.
Стандартный логический тип Boolean (размер-1 байт) представляет собой тип данных, любой элемент которого может принимать лишь 2 значения: True и False.
Над логическими элементами данных выполняются логические операции. Основные из них:
а) Отрицание (NOT). б) Конъюнкция (AND). в) Дизъюнкция (OR).
Таблица истинности основных логических функций
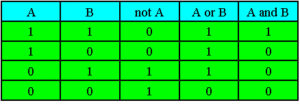
Рис. 3
Логические значения получаются также при реляционных операциях с целыми числами.
-
Символьный тип – CHAR.
Тип CHAR содержит 26 прописных латинских букв и 26 строчных,
10 арабских цифр и некоторое число других графических символов, например, знаки пунктуации.
Подмножества букв и цифр упорядочены и «соприкасаются», т.е. («A»<= x)&(x <= «Z») – x представляет собой прописную букву; («0»<= x)&(x <= «9») – x представляет собой цифру.
Тип CHAR содержит некоторый непечатаемый символ, пробел, его можно использовать как разделитель.
Операции:
а) Присваивания. б) Сравнения.
в) Определения номера данной литеры в системе кодирования.
ORD(Wi).
г) Нахождение литеры по номеру. CHR(i). д) Вызов следующей литеры. SUCC(Wi). е) Вызов предыдущей литеры. PRED(Wi).
-
Указательный тип – POINTER.
Переменная типа указатель является физическим носителем адреса величины базового типа. Cтандартный тип-указатель Pointer дает указатель, не связанный ни с каким конкретным базовым типом. Этот тип совместим с любым другим типом-указателем.
Операции:
а) Присваивания.
б) Операции с беззнаковыми целыми числами.
При помощи этих операций можно вычислить адрес данных. В машинном виде эти типы занимают максимально возможную длину.
Например:
ABCD:1234 – значение указателя в шестнадцатеричной системе счисления – относительный адрес.
Первое число (ABCD) – адрес сегмента. Второе число (1234) – адрес внутри сегмента.
Получение абсолютного адреса из относительного:
Для получения абсолютного адреса необходимо произвести сдвиг адреса сегмента влево, и к полученному числу прибавить адрес внутреннего сегмента.
Например:
-
Сдвигаем ABCD на один разряд влево. Получаем АВСD0.
-
Прибавляем 1234. Полученный результат и является абсолютным адресом.
ABCD0 12 3 4
ACF04 – абсолютный адрес данного числа.
-
-
Стандартные типы пользователя.
-
Перечисляемый.
Перечисляемый тип определяется конечным набором значений, представленных списком идентификаторов в объявлении типа. Значениям из этого набора присваиваются номера в соответствии с той последовательностью, в которой перечислены идентификаторы. Формат объявления перечисляемого типа таков:
TYPE<имя> = (<список>);
<список>:= <идентификатор>,[<список>].
Если идентификатор указан в списке значений перечисляемого типа, он считается именем константы, определенной в том блоке, где объявлен перечисляемый тип. Порядковые номера значений в объявлении перечисляемого типа определяются их позициями в списке идентификаторов, причем у первой константы в списке порядковый номер равен нулю. К данным перечисляемого типа относится, например, набор цветов:
TYPE <Цвет> = (Красный, Зеленый, Синий)
Операции те же, что и для символьного типа.
-
Диапазонный или интервальный.
В любом порядковом типе можно выделить подмножество значений, определяемое минимальным и максимальным значениями, в которое входят все значения исходного типа, находящиеся в этих границах, включая сами границы. Такое подмножество определяет диапазонный тип. Он задаётся указанием минимального и максимального значений, разделенных двумя точками.
TYPE T=[ MIN..MAX ] TYPE <Час>=[1..60]
Минимальное значение при определении такого типа не должно быть больше максимального.
Вопрос 2. Статические и полустатические структуры данных.
Структуры данных – это совокупность элементов данных и отношений между ними. При этом под элементами данных может подразумеваться как простое данное так и структура данных. Под отношениями между данными понимают функциональные связи между ними и указатели на то, где находятся эти данные.
Графическое представление элемента структуры данных.
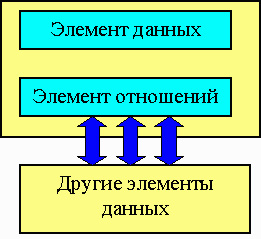
Рис. 4
Элемент отношений – это совокупность всех связей элемента с другими элементами данных, рассматриваемой структуры.
S:=(D,R)
где
S – структура данных,
D – данные и R – отношения.
Как бы сложна ни была структура данных, в конечном итоге она состоит из простых данных (см. рис. 5, 6).

Рис. 5
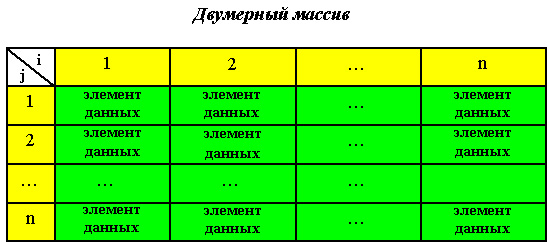
Рис. 6
-
Уровни представления данных.
Внутренний мир ЭВМ далеко не так прост, как мы думаем. Память машины состоит из миллионов триггеров, которые обрабатывают поступающую информацию
Мы, занося информацию в компьютер, представляем ее в каком-то виде, который на наш взгляд упорядочивает данные и придает им смысл. Машина отводит поле для поступающей информации и задает ей какой- то адрес. Таким образом получается, что мы обрабатываем данные на логическом уровне, как бы абстрактно, а машина делает это на физическом уровне.
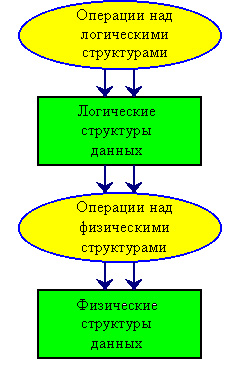
Рис. 7
Последовательность переходов от логической организации к физической показана на рис. 7.
-
Классификация структур данных.
Структуры данных классифицируются:
-
По связанности данных в структуре:
-
если данные в структуре связаны очень слабо, то такие структуры называются несвязанными (вектор, массив, строки, стеки);
-
если данные в структуре связаны, то такие структуры называются связанными (связанные списки).
-
-
По изменчивости структуры во времени или в процессе выполнения программы:
-
статические структуры – структуры, неменяющиеся до конца выполнения программы (записи, массивы, строки, вектора);
-
полустатические структуры (стеки, деки, очереди);
-
динамические структуры – происходит полное изменение при выполнении программы.
-
-
По упорядоченности структуры:
-
линейные (вектора, массивы, стеки, деки, записи);
-
нелинейные (многосвязные списки, древовидные структуры, графы).
Наиболее важной характеристикой является изменчивость структуры во времени.
3. Статические структуры данных.
-
Векторы.
Самая простая статическая структура – это вектор. Вектор – это чисто линейная упорядоченная структура, где отношение между ее элементами есть строго выраженная последовательность элементов структуры (рис. 8).
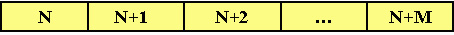
Рис. 8
Каждый элемент вектора имеет свой индекс, определяющий положение данного элемента в векторе. Поскольку индексы являются целыми числами, над ними можно производить операции и, таким образом, вычислять положение элемента в структуре на логическом уровне доступа. Для доступа к элементу вектора, достаточно просто указать имя вектора (элемента) и его индекс.
Для доступа к этому элементу используется функция адресации, которая формирует из значения индекса адрес слота, где находится значение исходного элемента. Для объявления в программе вектора необходимо указать его имя, количество элементов и их тип (тип данных)
Пример:
var
M1: Array [1…100] of integer; M2: Array [1…10] of real;
Вектор состоит из совершенно однотипных данных и количество их строго определено.
-
Массивы.
В общем случае элемент массива – это есть элемент вектора, который сам по себе тоже является элементом структуры (рис. 9).
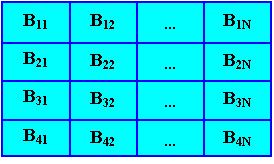
Рис. 9
Для доступа к элементу двумерного массива необходимы значения пары индексов (номер строки и номер столбца, на пересечении которых находится элемент). На физическом уровне двумерный массив выглядит также, как и одномерный (вектор), причем трансляторы представляют массивы либо в виде строк, либо в виде столбцов.
-
Записи.
Запись представляет из себя структуру данных последовательного типа, где элементы структуры расположены один за другим как в логическом, так и в физическом представлении. Запись предполагает множество элементов разного типа. Элементы данных в записи часто называют полями записи.
Пример:

Рис. 10
Логическая структура записи может быть представлена как в графическом виде, так и в табличном.

Рис. 11
Рис. 12
Элемент записи может включать в себя записи. В этом случае возникает сложная иерархическая структура данных.
Пример:
Необходимо заполнить запись о студенте, содержащую следующую информацию: N – порядковый номер студента; Имя студента, в составе которого должны быть: Фамилия, Имя, Отчество; Анкетные данные студента: год рождения, место рождения, родители: мать, отец; Факультет; Группа; Оценки, полученные в сессию: по английскому языку и микропроцессорам.
Ниже приведены два логических представления структуры этой записи.
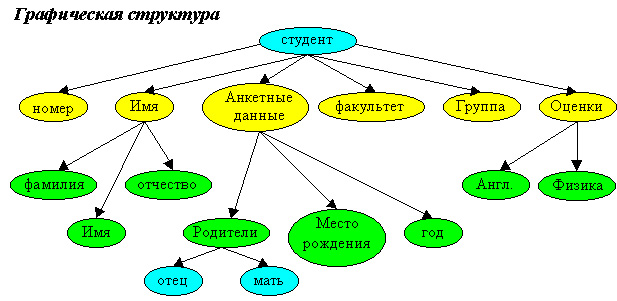
Рис. 13
Получена четырехуровневая иерархическая структура данных. Информация содержится в листьях, остальные узлы служат для указания пути к листьям.
1-ый уровень Студент = запись
2-ой уровень Номер
2-ой уровень Имя = запись
3-ий уровень Фамилия
3-ий уровень Имя
3-ий уровень Отчество
2-ой уровень Анкетные данные = запись
3-ий уровень Место рождения
3-ий уровень Год рождения
3-ий уровень Родители = запись
4-ый уровень Мать
4-ый уровень Отец
2-ой уровень Факультет
2-ой уровень Группа
2-ой уровень Оценки = запись
3-ий уровень Английский
3-ий уровень ФизикаЭта структура называется вложенной записью.
Операции над записями:
-
Прочтение содержимого поля записи.
-
Занесение информации в поле записи.
-
Все операции, которые разрешаются над полем записи, соответствующего типа.
-
-
Таблицы.
Таблица – это конечный набор записей (рис. 14).
-
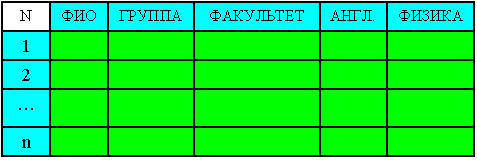
Рис. 14
При задании таблицы указывается количество содержащихся в ней записей.
Пример:
Type ST = Record
Num: Integer; Name: String[15]; Fak: String[5]; Group: String[10]; Angl: Integer; Physic: Integer;
var
Table: Array [1..19] of St;
Элементом данных таблицы является запись. Поэтому операции, которые производятся с таблицей – это операции, производимые с записью.
Операции с таблицами:
-
Поиск записи по заданному ключу.
-
Занесение новой записи в таблицу.
Ключ – это идентификатор записи. Для хранения этого идентификатора отводится специальное поле.
Составной ключ – ключ, содержащий более двух полей.
4. Полустатические структуры данных.
К полустатическим структурам данных относят стеки, деки и очереди.
Списки
Это набор связанных элементов данных, которые в общем случае могут быть разного типа.
Пример списка:
E1, E2,…….., En,… n > 1 и не зафиксировано.
Количество элементов списка может меняться в процессе выполнения программы. Различают 2 вида списков:
-
Несвязные.
-
Связные.
В несвязных списках связь между элементами данных выражена неявно. В связных списках в элемент данных заносится указатель связи с последующим или предыдущим элементом списка.
Стеки, деки и очереди – это несвязные списки. Кроме того они относятся к последовательным спискам, в которых неявная связь отображается их последовательностью.
-
Стеки.
Очередь вида LIFO (Last In First Out – Последним пришел, первым ушел), при которой на обслуживание первым выбирается тот элемент очереди, который поступил в нее последним, называется стеком. Это одна из наиболее употребляемых структур данных, которая оказывается весьма удобной при решении различных задач.
В силу указанной дисциплины обслуживания, в стеке доступна единственая его позиция, которая называется вершиной стека- это позиция, в которой находится последний по времени поступления в стек элемент. Когда мы заносим новый элемент в стек, то он помещается поверх прежней вершины и теперь уже сам находится в вершине стека. Выбрать элемент можно только из вершины стека; при этом выбранный элемент исключается из стека, а в его вершине оказывается элемент, который был занесен в стек перед выбранным из него элементом (структура с ограниченным доступом к данным).
Графически стек можно представить следующим образом:
Рис. 15
Первый элемент заносится вниз стека. Выборка из стека осуществляется с вершины, поэтому стек является структурой с ограниченным доступом.
Операции, производимые над стеками:
-
Занесение элемента в стек.
Push(S,I), где S – идентификатор стека, I – заносимый элемент.
-
Выборка элемента из стека. Pop(S)
-
Определение пустоты стека. Empty(S)
-
Прочтение элемента без его выборки из стека. StackTop(S)
Пример реализации стека на Паскале с использованием одномерного массива:
type
Stack = Array[1..10] of Integer; {стек вместимостью 10 элементов типа Integer}
var
StackCount: Integer; {Переменная – указатель на вершину стека,
ее начальное значение должно быть равно 0} S: Stack; {Объявление стека}
Procedure Push(I: Integer; var S: Stack); begin
Inc(StackCount); S[StackCount]:=I; end;
Procedure Pop(var I: Integer; S: Stack); begin
I:=S[StackCount]; Dec(StackCount); end;
Function Empty: Boolean; begin
If I = 0 then Empty:=True Else Empty:=False; end;
При выполнении операции выборки из стека сначала необходимо осуществить проверку на пустоту стека. Если он пуст, то Empty возвращает значение True. Если Empty возвращает False, то это означает, что стек не пуст и из него еще можно выбирать элементы.
Procedure StackTop(var I: Integer; S: Stack); begin
I:=S[StackCount]; end;
-
-
Очередь.
Понятие очереди всем хорошо известно из повседневной жизни. Элементами очереди в общем случае являются заказы на то или иное обслуживание.
В программировании имеется структура данных, которая называется очередью. Эта структура данных используется, например, для моделирования реальных очередей с целью определения их характеристик при данном законе поступления заказов и дисциплине их обслуживания. По своему существу очередь является полустатической структурой- с течением времени и длина очереди, и состав могут изменяться.
На рис. 2. 13 приведена очередь, содержащая четыре элемента — А, В, С и D. Элемент А расположен в начале очереди, а элемент D — в ее конце. Элементы могут удаляться только из начала очереди, то есть первый помещаемый в очередь элемент удаляется первым. По этой причине очередь часто называют списком, организованным по принципу «первый размещенный первым удаляется» в противоположность принципу стековой организации — «последний размещенный первым удаляется».
Дисциплину обслуживания, в которой заказ, поступивший в очередь первым, выбирается первым для обслуживания (и удаляется из очереди), называется FIFO (First In First Out – Первым пришел, первым ушел). Очередь открыта с обеих сторон.
Таким образом, изъятие компонент происходит из начала очереди, а запись- в конец. В этом случае вводят два указателя: один – на начало очереди, второй- на ее конец.
Реальная очередь создается в памяти ЭВМ в виде одномерного массива с конечным числом элементов, при этом необходимо указать тип элементов очереди, а также необходима переменная в работе с очередью.
Рис. 16
Физически очередь занимает сплошную область памяти и элементы следуют друг за другом, как в последовательном списке.
Операции, производимые над очередью:
Для очереди определены три примитивные операции. Операция insert (q,x) помещает элемент х в конец очереди q. Операция remove(q) удаляет элемент из начала очереди q и присваивает его значение переменной х. Третья операция, empty (q), возвращает значение true или false в зависимости от того, является ли данная очередь пустой или нет. Кроме того. Учитывая то, что полустатическая очередь реализуется на одномерном массиве, необходимо следить за возможностью его переполнения. Сэтой целью вводится опнрация full(q).
Операция insert может быть выполнена всегда, поскольку на количество элементов, которые может содержать очередь, никаких ограничений не накладывается. Операция remove, однако, применима только к непустой очереди, поскольку невозможно удалить элемент из очереди, не содержащей элементов. Результатом попытки удалить элемент из пустой очереди является возникновение исключительной ситуации потеря значимости. Операция empty, разумеется, выполнима всегда.
Пример реализации очереди в виде одномерного массива на Паскале:
const
MaxQ =…
type
E =…
Queue = Array [1..MaxQ] of E;
var
Q: Queue;
F, R: Integer;
{Указатель F указывает на начало очереди. Указатель R указывает на конец очереди. Если очередь пуста, то F = 1, а R = 0 (То есть R < F – условие пустоты очереди).}
Procedure Insert(I: Integer; var Q: Queue); begin
Inc(R);
Q[R]:=I;
end;
Function Empty(Q: Queue): Boolean; begin
If R < F then Empty:=True Else Empty:=False; end;
Procedure Remove(var I: Integer; Q: Queue); begin
If Not Empty(Q) then begin
end;
end;
I:=Q[F];
Inc(F);
Пример работы с очередью с использованием стандартных процедур.
MaxQ = 5
Рис. 17
Производим вставку элементов A, B и C в очередь. Insert(q, A);
Insert(q, B);
Insert(q, C);
Рис. 18
Убираем элементы A и B из очереди. Remove(q);
Remove(q);
Рис. 19
К сожалению, при подобном представлении очереди, возможно возникновение абсурдной ситуации, при которой очередь является пустой, однако новый элемент разместить в ней нельзя (рассмотрите последовательность операций удаления и вставки, приводящую к такой ситуации). Ясно, что реализация очереди при помощи массива является неприемлемой.
Одним из решений возникшей проблемы может быть модификация операции remove таким образом, что при удалении очередного элемента вся очередь смещается к началу массива. Операция remove (q) может быть в этом случае реализована следующим образом.
X = q[1]
For I =1 to R-1 q[I] =q[I+1]
next I R =R-1
Переменная F больше не требуется, поскольку первый элемент массива всегда является началом очереди. Пустая очередь представлена очередью, для которой значение R равно нулю.
Однако этот метод весьма непроизводителен. Каждое удаление требует перемещения всех оставшихся в очереди элементов. Если очередь содержит 500 или 1000 элементов, то очевидно, что это весьма неэффективный способ. Далее, операция удаления элемента из очереди логически предполагает манипулирование только с одним элементом, т. е. с тем, который расположен в начале очереди. Реализация данной операции должна отражать именно этот факт, не производя при этом множества дополнительных действий.
Другой способ предполагает рассматривать массив, который содержит очередь в виде замкнутого кольца, а не линейной последовательности, имеющей начало и конец. Это означает, что первый элемент очереди следует сразу же за последним. Это означает, что даже в том случае, если последний элемент занят, новое значение может быть размещено сразу же за ним на месте первого элемента, если этот первый элемент пуст.
Организация кольцевой очереди.
Рис. 20
Рассмотрим пример. Предположим, что очередь содержит три элемента – в позициях 3, 4 и 5 пятиэлементного массива. Этот случай, показанный на рис. 20. Хотя массив и не заполнен, последний элемент очереди занят.
Если теперь делается попытка поместить в очередь элемент G, то он будет записан в первую позицию массива, как это показано на рис. 2.17. Первый элемент очереди есть Q(3), за которым следуют элементы Q (4), Q(5) и Q(l).
К сожалению, при таком представлении довольно трудно определить, когда очередь пуста. Условие R<F больше не годится для такой проверки, поскольку на рис. 2. 17 показан случай, при котором данное условие выполняется, но очередь при этом не является пустой.
Одним из способов решения этой проблемы является введение соглашения, при котором значение F есть индекс элемента массива, немедленно предшествующего первому элементу очереди, а не индексу самого первого элемента. В этом случае, поскольку R содержит индекс последнего элемента очереди, условие F = R подразумевает, что очередь пуста.
Отметим, что перед началом работы с очередью, в F и R устанавливается значение последнего индекса массива, а не 0 и 1, поскольку при таком представлении очереди последний элемент массива немедленно предшествует первому элементу. Поскольку R = F, то очередь изначально пуста.
Основные операции с кольцевой очередью:
-
Вставка элемента q в очередь x. Insert(q,x)
-
Извлечение элемента из очереди x. Remove(q)
-
Проверка очереди на пустоту. Empty(q)
Операция empty (q) может быть записана следующим образом: if F = R
then empty = true
else empty = false endif
return
Операция remove (q) может быть записана следующим образом: empty (q)
if empty = true
then print «выборка из пустой очереди» stop
endif
if F =maxQ
then F =1 else F = F+1
endif
x = q(F) return
Отметим, что значение F должно быть модифицировано до момента извлечения элемента.
Операция вставки insert (q,x).
Для того чтобы запрограммировать операцию вставки, должна быть проанализирована ситуация, при которой возникает переполнение. Переполнение происходит в том случае, если весь массив уже занят элементами очереди и при этом делается попытка разместить в ней еще один элемент. Рассмотрим, например, очередь на рис. 2. 17. В ней находятся три элемента — С, D и Е, соответственно расположенные в Q (3), Q (4) и Q (5). Поскольку последний элемент в очереди занимает позицию Q (5), значение R равно 5. Так как первый элемент в очереди находится в Q (3), значение F равно 2. На рис. 2. 17 в очередь помещается элемент G, что приводит к соответствующему изменению значения R. Если произвести следующую вставку, то массив становится целиком заполненным, и попытка произвести еще одну вставку приводит к переполнению. Это регистрируется тем фактом, что F = R, а это как раз и указывает на переполнение. Очевидно, что при такой реализации нет возможности сделать различие между пустой и заполненной очередью Разумеется, такая ситуация удовлетворить нас не может
Одно из решений состоит в том, чтобы пожертвовать одним элементом массива и позволить очереди расти до объема на единицу меньшего максимального. Так, если массив из 100 элементов объявлен как очередь, то очередь может содержать до 99 элементов. Попытка разместить в очереди 100-й элемент приведет к переполнению. Подпрограмма insert может быть записана следующим образом:
if R = max(q) then R = 1 else R = R+1
endif
‘проверка на переполнение if R = F
then print «переполнение очереди» stop
endif
q (r) =x return
Проверка на переполнение в подпрограмме insert производится после установления нового значения для R, в то время как проверка на потерю значимости в подпрограмме remove производится сразу же после входа в подпрограмму до момента обновления значения F.
-
-
Дек.
От английского DEQ – Double Ended Queue (Очередь с двумя концами).
Особенностью деков является то, что запись и считывание элементов может производиться с двух концов (рис. 21).
Рис. 21
Дек можно рассматривать и в виде двух стеков, соединенных нижними границами. Возьмем пример, иллюстрирующий принцип построения дека. Рассмотрим состав на железнодорожной станции. Новые вагоны к составу можно добавлять либо к его концу, либо к началу. Аналогично, чтобы отсоединить от состава вагон, находящийся в середине, нужно сначала отсоединить все вагоны или вначале, или в конце состава, отсоединить нужный вагон, а затем присоединить их снова.
Операции над деками:
-
Insert – вставка элемента.
-
Remove – извлечение элемента из дека.
-
Empty – проверка на пустоту.
-
Full – проверка на переполнениe.
Вопрос 3. Динамические структуры данных.
До сих пор мы рассматривали только статические программные объекты. Однако использование при программировании только статических объектов может вызвать определенные трудности, особенно с точки зрения получения эффективной машинной программы. Дело в том, что иногда мы заранее не знаем не только размера значения того или иного программного объекта, но также и того, будет ли существовать этот объект или нет. Такого рода программные объекты, которые возникают уже в процессе выполнения программы или размер значений которых определяется при выполнении программы, называются динамическими объектами.
Динамические структуры данных имеют 2 особенности:
-
Заранее не определено количество элементов в структуре.
-
Элементы динамических структур не имеют жесткой линейной упорядоченности. Они могут быть разбросаны по памяти.
Чтобы связать элементы динамических структур между собой в состав элементов помимо информационных полей входят поля указателей (рис. 22) (связок с другими элементами структуры).
Рис. 22
P1 и P2 это указатели, содержащие адреса элементов, с которыми они связаны. Указатели содержат номер слота.
-
-
Связные списки.
Наиболее распространенными динамическими структурами являются связанные списки. С точки зрения логического представления различают линейные и нелинейные списки.
В линейных списках связи строго упорядочены: указатель предыдущего элемента содержит адрес последующего элемента или наоборот.
К линейным спискам относятся односвязные и двусвязные списки.
К нелинейным – многосвязные.
Элемент списка в общем случае представляет собой поле записи и одного или нескольких указателей.
-
Односвязные списки.
Элемент односвязного списка содержит два поля (рис. 23): информационное поле (INFO) и поле указателя (PTR).
Рис. 23
Особенностью указателя является то, что он дает только адрес последующего элемента списка. Поле указателя последнего элемента в списке является пустым (NIL). LST – указатель на начало списка. Список может быть пустым, тогда LST будет равен NIL.
Доступ к элементу списка осуществляется только от его начала, то есть обратной связи в этом списке нет.
-
Кольцевой односвязный список.
Кольцевой односвязный список получается из обычного односвязного списка путем присваивания указателю последнего элемента списка значение указателя начала списка (рис 24).
Рис. 24
Простейшие операции, производимые над односвязными списками.
-
Вставка в начало односвязного списка.
Надо вставить в начало односвязного списка элемент с информационным полем D. Для этого необходимо сгенерировать пустой элемент (P=GetNode). Информационному полю этого элемента присвоить значение D (INFO(P)=D), значению указателя на этот элемент присвоить значение указателя на начало списка (Ptr(P) = Lst), значению указателя начала списка присвоить значение указателя P (Lst = P).
Реализация на Паскале:
type
PNode = ^TNode; TNode = record
Info: Integer; {тип элементов списка – может быть любым}
Next: PNode;
end; var
Lst: PNode; {указатель на начало списка}
P: PNode; Вставка в начало
New(P); {создание нового элемента}
P^.Info:=D;
P^.Next:=Lst; {P указывает на начало списка, но Lst не указывает на P – новое начало}
Lst:=P; {Lst указывает на новое начало списка}
-
Удаление элемента из начала односвязного списка.
Надо удалить первый элемент списка, но запомнить информацию, содержащуюся в поле Info этого элемента. Для этого введем указатель P, который будет указывать на удаляемый элемент (P = Lst). В переменную X занесем значение информационного поля Info удаляемого элемента (X=Info(P)). Значению указателя на начало списка присвоим значение указателя следующего за удаляемым элемента (Lst = Ptr(P)). Удалим элемент (FreeNode(P)).
Реализация на Паскале:
Удаление из начала P:=Lst;
X:=P^.Info;
Lst:=P^.Next;
Dispose(P); {Удаляет элемент из динамической памяти}
-
Двусвязный список.
Использование однонаправленных списков при решении ряда задач может вызвать определенные трудности. Дело в том, что по однонаправленному списку можно двигаться только в одном направлении, от заглавного звена к последнему звену списка. Между тем нередко возникает необходимость произвести какую-либо обработку элементов, предшествующих элементу с заданным свойством. Однако после нахождения элемента с этим свойством в односвязном списке у нас нет возможности получить достаточно удобный и быстрый доступ к предыдущим элементам- для достижения этой цели придется усложнить алгоритм, что неудобно и нерационально.
Для устранения этого неудобства добавим в каждое звено списка еще одно поле, значением которого будет ссылка на предыдущее звено списка. Динамическая структура, состоящая из элементов такого типа, называется двунаправленным или двусвязным списком.
Двусвязный список характеризуется тем, что у любого элемента есть два указателя. Один указывает на предыдущий элемент (обратный), другой указывает на следующий элемент (прямой) (рис. 25).
Рис. 25
Фактически двусвязный список это два односвязных списка с одинаковыми элементами, записанных в противоположной последовательности.
-
Кольцевой двусвязный список.
В программировании двусвязные списки часто обобщают следующим образом: в качестве значения поля Rptr последнего звена принимают ссылку на заглавное звено, а в качестве значения поля Lptr заглавного звена- ссылку на последнее звено. Список замыкается в своеобразное кольцо: двигаясь по ссылкам, можно от последнего звена переходить к заглавному и наоборот.
Рис. 26 Операции над двусвязными списками:
-
-
-
cоздание элемента списка;
-
поиск элемента в списке;
-
вставка элемента в указанное место списка;
-
удаление из списка заданного элемента.
-
Реализация стеков с помощью односвязных списков.
Любой односвязный список может рассматриваться в виде стека. Однако список по сравнению со стеком в виде одномерного массива имеет преимущество, так как заранее не задан его размер.
Стековые операции, применимые к спискам.
-
Чтобы добавить элемент в стек, надо в алгоритме заменить указатель Lst на указатель Stack (операция Push(S, X)).
P = GetNode Info(P) = X Ptr(P) = Stack Stack = P
-
Проверка стека на пустоту (Empty(S)).
If Stack = Nil then Print “Стек пуст” Stop
-
Выборка элемента из стека (POP(S)).
P = Stack X = Info(P)
Stack = Ptr(P) FreeNode(P)
Реализация на Паскале:
Стек.
Вместо указателя Lst используется указатель Stack. Процедура Push (S, X).
procedure Push(var Stack: PNode; X: Integer); var
P: PNode; begin
New(P);
P^.Info:=X;
P^.Next:=Stack;
Stack:=P;
end;
Проверка на пустоту (Empty).
function Empty(Stack: PNode): Boolean; begin
If Stack = nil then Empty:=True Else Empty:=False; end;
Процедура Pop.
procedure Pop(var X: Integer; var Stack: PNode); var
P: PNode; begin
P:=Stack;
X:=P^.Info;
Stack:=P^.Next;
Dispose(P);
end;
Операции с очередью, применимые к спискам.
Указатель начала списка принимаем за указатель начала очереди F, а указатель R, указывающий на последний элемент списка – за указатель конца очереди.
-
Операция удаления из очереди (Remove(Q, X)).
Операция удаления из очереди должна проходить из ее начала.
P = F
F = Ptr(P)
X = Info(P) FreeNode(P)
-
Проверка очереди на пустоту. (Empty(Q)) If F = Nil then Print “Очередь пуста”
Stop
-
Операция вставки в очередь. (Insert(Q, X))
Операция вставки в очередь должна осуществляться к ее концу.
P = GetNode Info(P) = X Ptr(P) = Nil Ptr(R)= P
R = P
Реализация на Паскале:
procedure Remove(var X: Integer; Fr: PNode); var
P: PNode; begin
New(P); P:=Fr;
X:=P^.Info;
Fr:=P^.Next;
Dispose(P);
end;
function Empty(Fr: PNode): Boolean; begin
If Fr = nil then Empty:=True Else Empty:=False; end;
procedure Insert(X: Insert; var Re: PNode); var
P: PNode; begin
New(P);
P^.Info:=X;
P^.Next:=nil;
Re^.Next:=P;
end;
-
-
Организация операций Getnode, Freenode и утилизация освободившихся элементов.
Для более эффективного использования памяти компьютера (для исключения мусора, то есть неиспользуемых элементов) при работе его со списками создается свободный список, имеющий тот же формат полей, что и у функциональных списков.
Если у функциональных списков разный формат, то надо создавать свободный список каждого функционального списка.
Количество элементов в свободном списке должно быть определено задачей, которую решает программа. Как правило, свободный список создается в памяти машины как стек. При этом создание (GetNode) нового элемента эквивалентно выборке элемента свободного стека, а операция FreeNode – добавлению в свободный стек освободившегося элемента.
Пусть нам необходимо создать пустой список по типу стека (рис. 27) с указателем начала списка – AVAIL. Разработаем процедуры, которые позволят нам создавать пустой элемент списка и освобождать элемент из списка.
Рис. 27
-
Операция GetNode.
Разработаем процедуру, которая будет создавать пустой элемент списка с указателем Р.
Для реализации операции GetNode необходимо указателю сгенерированного элемента присвоить значение указателя начала свободного списка, а указатель начала перенести к следующему элементу.
P = Avail
Avail = Ptr(Avail)
Перед этим надо проверить, есть ли элементы в списке. Пустота свободного списка (Avail = Nil), эквивалентна переполнению функционального списка.
If Avail = Nil then Print “Переполнение” Stop Else
P = Avail
Avail = Ptr(Avail) Endif
-
Операция FreeNode.
При освобождении элемента Nod(P) из функционального списка операцией FreeNode(P), он заносится в свободный список.
Ptr(P) = Avail Avail = P
-
Утилизация освободившихся элементов в многосвязных списках.
Стандартные операции возвращения освободившегося элемента списка в пул свободных элементов не всегда дают эффект, если используются нелинейные многосвязные списки.
Первый способ утилизации – метод счетчиков. В каждый элемент многосвязного списка вставляется поле счетчика, который считает количество ссылок на данный элемент. Когда счетчик элемента оказывается в нулевом состоянии, а поля указателей элемента находятся в состоянии nil, этот элемент может быть возвращен в пул свободных элементов.
Второй способ – метод сборки мусора (метод маркера). Если с каким-то элементом установлена связь, то однобитовое поле элемента (маркер) устанавливается в “1”, иначе – в “0”. По сигналу переполнения ищутся элементы, у которых маркер установлен в ноль, т. е. включается программа сборки мусора, которая просматривает всю отведенную память и возвращает в список свободных элементов все элементы, не помеченные маркером.
-
-
Односвязный список, как самостоятельная структура данных.
Просмотр односвязного списка может производиться только последовательно, начиная с головы (с начала) списка. Если необходимо просмотреть предыдущий элемент, то надо снова возвращаться к началу списка. Это – недостаток односвязных списков по сравнению со статическими структурами типа массива. Списковая структура проявляет свои достоинства, когда число элементов списка велико, а вставку или удаление необходимо произвести внутри списка.
Пример:
Необходимо вставить в существующий массив элемент X между 5 и 6 элементами.
Рис. 28
Для проведения данной операции в массиве нужно “опустить” все элементы, начиная с X6 – увеличить их индексы на единицу. В результате вставки получаем следующий массив (рис. 28, 29):
Рис. 29
Данная процедура может занимать очень значительное время. В противоположность этому, в связанном списке операция вставки состоит в изменении значения 2-х указателей и генерации свободного элемента. Причём время, затраченное на выполнение этой операции, является постоянным и не зависит от количества элементов в списке.
1) Вставка и извлечение элементов из списка.
Определяем элемент, после которого необходимо вставить элемент в список. Вставка производится с помощью процедуры InsAfter(Q, X), а удаление – DelAfter(Q, X).
При этом рабочий указатель P будет указывать на элемент, после которого необходимо произвести вставку или удаление (рис 30).
Рис. 30
Пример:
Пусть необходимо вставить новый элемент с информационным полем X после элемента, на который указывает рабочий указатель P.
Для этого:
-
Необходимо сгенерировать новый элемент.
Q = GetNode
-
Информационному полю этого элемента присвоить значение X.
Info(Q) = X
-
Вставить полученный элемент.
Ptr(Q) = Ptr(P) Ptr(P) = Q
Это и есть процедура InsAfter(Q, X).
Пусть необходимо удалить элемент списка, который следует после элемента, на который указывает рабочий указатель P.
Для этого:
-
Присваиваем Q значение указателя на удаляемый элемент.
Q = Ptr(P)
-
В переменную X сохраняем значение информационного поля удаляемого элемента.
X = Info(Q)
-
Меняем значение указателя на удаляемый элемент на значение указателя на следующий элемент и производим удаление.
Ptr(P) = Ptr(Q) FreeNode(Q)
Это и есть процедура DelAfter(P, X).
На языке Паскаль вышеописанные процедуры будут выглядеть следующим образом:
procedure InsAfter(var Q: PNode; X: Integer); var
Q: PNode; begin
New(Q);
Q^.Info:=X; Q^.Next:=P^.Next; P^.Next:=Q;
procedure DelAfter(var Q: PNode; var X: Integer); var
Q: PNode; begin
Q:=P^.Next; P^.Next:=Q^.Next; X:=Q^.Info; Dispose(Q);
end;
-
Примеры типичных операций над списками. Задача 1.
Требуется просмотреть список и удалить элементы, у которых информационные поля равны 4.
Обозначим P – рабочий указатель, в начале процедуры P = Lst. Введем также указатель Q, который отстает на один элемент от P. Когда указатель P найдет элемент, последний будет удален относительно указателя Q как последующий элемент.
Q = Nil P = Lst
While P <> Nil do
If Info(P) = 4 then If Q = Nil then
Pop(Lst) FreeNode(P) P = Lst
Else
EndIf Else
Q = P
DelAfter(Q, X)
P = Ptr(P)
EndIf EndWhile
Задача 1.
Дан упорядоченный по возрастанию Info – полей список. Необходимо вставить в этот список элемент со значением X, не нарушив упорядоченности списка.
Рис. 31
Пусть X = 16. Начальное условие: Q = Nil, P = Lst. Вставка элемента должна произойти между 3 и 4 элементом (рис. 31).
Q =Nil P = Lst
While (P <> Nil) and (X > Info(P)) do Q = P
P = Ptr(P)
EndWhile
if Q = Nil then Push(Lst, X)
EndIf InsAfter(Q, X)
Реализация примеров на языке Паскаль:
Задача 2: Q:=nil; P:=Lst;
While P <> nil do
If P^.Info = 4 then begin
If Q = nil then
begin
end
Pop(Lst); P:=Lst;
End;
Else
begin
end; end;
Else Delafter(Q,X);
Q:=P;
P:=P^.Next;
Задача 2:
Q:=nil; P:=Lst;
While (P <> nil) and (X > P^.Info) do begin
Q:=P;
P:=P^.Next; end;
{В эту точку производится вставка} If Q = nil then Push(Lst, X); InsAfter(Q, X);
End;
-
Элементы заголовков в списках.
Для создания списка с заголовком в начало списка вводится дополнительный элемент, который может содержать информацию о списке (рис. 32).
Рис. 32
В заголовок списка часто помещают динамическую переменную, содержащую количество элементов в списке (не считая самого заголовка).
Если список пуст, то остается только заголовок списка (рис. 33).
Рис. 33
Также удобно занести в информационное поле заголовка значение указателя конца списка. Тогда, если список используется как очередь, то Fr = Lst, а Re = Info(Lst).
Информационное поле заголовка можно использовать для хранения рабочего указателя при просмотре списка P = Info(Lst). То есть заголовок
-
это дескриптор структуры данных.
-
-
Нелинейные связанные структуры.
Двусвязный список может быть нелинейной структурой данных, если вторые указатели задают произвольный порядок следования элементов (рис. 34).
Рис. 34
LST1 – указатель на начало 1 – ого списка (ориентированного указателем P1). Он линейный и состоит из 5-и элементов.
2-ой список образован из этих же самых элементов, но в произвольной последовательности. Началом 2-ого списка является 3-ий элемент, а концом 2-ой элемент.
В общем случае элемент списочной структуры может содержать сколь угодно много указателей, то есть может указывать на любое количество элементов.
Можно выделить 3 признака отличия нелинейной структуры:
-
Любой элемент структуры может ссылаться на любое число других элементов структуры, то есть может иметь любое число полей- указателей.
-
На данный элемент структуры может ссылаться любое число других элементов этой структуры.
-
Ссылки могут иметь вес, то есть подразумевается иерархия ссылок.
Представим, что имеется дискретная система, в графе состояния которой узлы – это состояния, а ребра – переходы из состояния в состояние (рис. 35).
Рис. 35
Входной сигнал в систему это X. Реакцией на входной сигнал является выработка выходного сигнала Y и переход в соответствующее состояние.
Граф состояния дискретной системы можно представит в виде двусвязного нелинейного списка. При этом в информационных полях должна записываться информация о состояниях системы и ребрах. Указатели элементов должны формировать логические ребра системы (рис. 36).
Для реализации вышесказанного:
-
должен быть создан список, отображающий состояния системы (1, 2, 3);
-
должны быть созданы списки, отображающие переходы по ребрам из соответствующих состояний.
Рис. 36
В общем случае при реализации многосвязной структуры получается сеть.
Вопрос 4. Рекурсивные структуры данных.
Рассмотрим рекурсивные алгоритмы и рекурсивные структуры данных.
Рекурсия – процесс, протекание которого связано с обращением к самому себе (к этому же процессу).
Пример рекурсивной структуры данных – структура данных, элементы которой являются такими же структурами данных (рис. 37).
Рис. 37
-
Деревья.
Дерево – нелинейная связанная структура данных (рис. 38).
Рис. 38
Дерево характеризуется следующими признаками:
-
-
дерево имеет 1 элемент, на которого нет ссылок от других элементов. Этот элемент называется корнем дерева;
-
в дереве можно обратиться к любому элементу путем прохождения конечного числа ссылок (указателей);
-
каждый элемент дерева связан только с одним предыдущим элементом, Любой узел дерева может быть промежуточным либо терминальным (листом). На рис. 4.2 промежуточными являются элементы M1, M2, листьями – A, B, C, D, E. Характерной особенностью терминального узла является отсутствие ветвей.
Высота – это количество уровней дерева. У дерева на рис. 4.2 высота равна двум.
Количество ветвей, растущих из узла дерева, называется степенью исхода узла (на рис. 4.2 для M1 степень исхода 2, для М2 – 3). По степени исхода классифицируются деревья:
-
если максимальная степень исхода равна m, то это – m-арное дерево;
-
если степень исхода равна либо 0, либо m, то это – полное m- арное дерево;
-
если максимальная степень исхода равна 2, то это – бинарное дерево;
-
если степень исхода равна либо 0, либо 2, то это – полное бинарное дерево.
Для описание связей между узлами дерева применяют также следующую терминологию: М1 – “отец” для элементов А и В. А и В – “сыновья” узла М1.
1) Представление деревьев.
Рис. 39. Графическая форма представления дерева и форма представления в виде нелинейного списка
Наиболее удобно деревья представлять в памяти ЭВМ в виде связанных списков. Элемент списка должен содержать информационные поля, в которых содержится значение узла и степень исхода, а также – поля-указатели, число которых равно степени исхода (рис. 39). То есть, любой указатель элемента ориентирует данный элемент-узел с сыновьями этого узла.
-
-
-
-
Бинарные деревья.
Бинарные деревья являются наиболее используемой разновидностью деревьев.
Согласно представлению деревьев в памяти ЭВМ каждый элемент будет записью, содержащей 4 поля. Значения этих полей будут соответственно ключ записи, ссылка на элемент влево-вниз, на элемент вправо-вниз и на текст записи.
При построении необходимо помнить, что левый сын имеет ключ меньший, чем у отца, а значение ключа правого сына больше значения ключа отца. Например, построим бинарное дерево из следующих элементов: 50, 46, 61, 48, 29, 55, 79. Оно имеет следующий вид:
Рис. 40
Получили упорядоченное бинарное дерево с одинаковым числом уровней в левом и правом поддеревьях. Это – идеально сбалансированное дерево, то есть дерево, в котором левое и правое поддеревья имеют уровни, отличающиеся не более чем на единицу.
Для создания бинарного дерева надо создавать в памяти элементы типа (рис. 41):
Рис. 41
Операция V = MakeTree(Key, Rec) – создает элемент (узел дерева) с двумя указателями и двумя полями (ключевым и информационным).
Вид процедуры MakeTree:
|
Псевдокод p = getnode r(p) = rec k(p) = key v = p left(p) = nil right(p) = nil |
Паскаль New(p); p^.r:= rec; p^.k:= key; v:= p; p^.left:= nil; p^.right:= nil; |
-
Сведение m-арного дерева к бинарному.
Неформальный алгоритм:
-
В любом узле дерева отсекаются все ветви, кроме крайней левой, соответствующей старшим сыновьям.
-
Соединяется горизонтальными линиями все сыновья одного родителя.
-
Старшим сыном в любом узле полученной структуры будет узел, находящийся под данным узлом (если он есть).
Последовательность действий алгоритма приведена на рис. 42.
Рис. 42
Рис. 43
Рис. 44. Сведение m-арного дерева к бинарному
-
-
Основные операции с деревьями.
-
Обход дерева.
-
Удаление поддерева.
-
Вставка поддерева.
Для выполнения обхода дерева необходимо выполнить три процедуры:
-
Обработка корня.
-
Обработка левой ветви.
-
Обработка правой ветви.
В зависимости от того, в какой последовательности выполняются эти три процедуры, различают три вида обхода.
-
Обход сверху вниз. Процедуры выполняются в последовательности
1-2-3.
-
Обход слева направо. Процедуры выполняются в последовательности
2 – 1- 3.
-
Обход снизу вверх. Процедуры выполняются в последовательности
2 – 3 -1.
В зависимости от того, какой по счету заход в узел приводит к обработке узла, получается реализация одного из трех видов обхода. Если обработка идет после первого захода в узел, то сверху вниз, если после второго, то слева направо, если после третьего, то снизу вверх (см. рис. 45).
Рис. 45. Различные направления обхода дерева
Операция исключения поддерева. Необходимо указать узел, к которому подсоединяется исключаемое поддерево и индекс этого поддерева. Исключение поддерева состоит в том, что разрывается связь с исключаемым поддеревом, т. е. указатель элемента устанавливается в nil, а степень исхода данного узла уменьшается на единицу.
Вставка поддерева – операция, обратная исключению. Надо знать индекс включаемого поддерева, узел, к которому подвешивается дерево, установить указатель этого узла на корень поддерева, а степень исхода данного узла увеличивается на единицу. При этом в общем случае необходимо произвести перенумерацию сыновей узла, к которому подвешивается поддерево.
Алгоритм вставки и удаления рассмотрен в главе 5.
-
-
Алгоритм создания дерева бинарного поиска.
Пусть заданы элементы с ключами: 14, 18, 6, 21, 1, 13, 15. После выполнения нижеприведенного алгоритма получится дерево, изображенное на рис. 46. Если обойти полученное дерево слева направо, то получим упорядочивание: 1, 6, 13, 14, 15, 18, 21.
Рис. 46
Псевдокод
read (key, rec)
tree = maketree(key rec) p = tree
q = tree
while not eof do read (key, rec)
v = maketree(key, rec) while p <> nil do
q = p
if key < k(p) then p = left(p)
else
p = right(p) endif endwhile
if key < k(q) then left(p) = v
else
right(p) = v endif
if q=tree then
‘ только корень’ endif
return
Паскаль
read (key, rec);
tree := maketree(key rec); p := tree;
q := tree;
while not eof do begin
read (key, rec);
v := maketree(key, rec); while p <> nil do
begin
q := p;
if key < p^.k then p := p^.left
else
p := p^.right; end;
if key < q^.k then p^.left := v
else
p^.right := v;
end
if q=tree
then writeln(‘Только корень’); exit
-
Прохождение бинарных деревьев.
В зависимости от последовательности обхода поддеревьев различают три вида обхода (прохождения) деревьев (рис.47):
Рис. 47. Прохождение бинарных деревьев
-
Сверху вниз А, В, С.
-
Слева направо или симметричное прохождение В, А, С.
-
Снизу вверх В, С, А.
Наиболее часто применяется второй способ.
Ниже приведены рекурсивные алгоритмы прохождения бинарных деревьев.
|
subroutine pretrave (tree) ‘сверху вниз if tree <> nil then print info(tree) pretrave(left(tree)) pretrave(right(tree)) endif return subroutine intrave (tree) ‘симметричный if tree <> nil then intrave(left(tree)) print info(tree) intrave(right(tree)) endif return |
Procedure pretrave (tree: tnode) Begin if tree <> nil then begin WriteLn(Tree^.Info); Pretrave(Tree^.left); Pretrave(Tree^.right); End; end; procedure intrave (tree: tnode) begin if tree <> nil then begin intrave(Tree^.left); writeLn(Tree^.info); intrave(Tree^.right); end; end; |
Рис. 48
Поясним подробнее рекурсию алгоритма обхода дерева слева направо.
Пронумеруем строки алгоритма intrave (tree):
-
if tree <> nil
-
then intrave (left(tree))
-
print info (tree)
-
intrave (right (tree))
-
endif
-
return
Обозначим указатели: t → tree; l → left; r → right.
На приведенном рис. 4.11 проиллюстрирована последовательность вызова процедуры intrave (tree) по мере обхода узлов простейшего дерева, изображенного на рис. 49.
Рис. 49. Иллюстрация рекурсивной работы процедуры intrave(tree) при обходе дерева на рис. 48.
Вопрос 5. Поиск.
Поиск является одной из основных операций при обработке информации в ЭВМ. Ее назначение – по заданному аргументу найти среди массива данных те данные, которые соответствуют этому аргументу.
Набор данных (любых) будем называть таблицей или файлом. Любое данное (или элемент структуры) отличается каким-то признаком от других данных. Этот признак называется ключом. Ключ может быть уникальным, т. е. в таблице существует только одно данное с этим ключом. Такой уникальный ключ называется первичным. Вторичный ключ в одной таблице может повторяться, но по нему тоже можно организовать поиск. Ключи данных могут быть собраны в одном месте (в другой таблице) или представлять собой запись, в которой одно из полей
-
это ключ. Ключи, которые выделены из таблицы данных и организованы в свой файл, называются внешними ключами. Если ключ находится в записи, то он называется внутренним.
Поиском по заданному аргументу называется алгоритм, определяющий соответствие ключа с заданным аргументом. Результатом работы алгоритма поиска может быть нахождение этого данного или отсутствие его в таблице. В случае отсутствия данного возможны две операции:
-
индикация того, что данного нет;
-
вставка данного в таблицу.
Пусть k – массив ключей. Для каждого k(i) существует r(i) – данное. Key – аргумент поиска. Ему соответствует информационная запись rec. В зависимости от того, какова структура данных в таблице, различают несколько видов поиска.
-
Последовательный поиск.
Применяется в том случае, если неизвестна организация данных или данные неупорядочены. Тогда производится последовательный просмотр по всей таблице начиная от младшего адреса в оперативной памяти и кончая самым старшим.
Последовательный поиск в массиве (переменная search хранит номер найденного элемента).
Рис. 50
for i:=1 to n
if k(i) = key then
search = i return
endif next i search = 0 return
На Паскале программа будет выглядеть следующим образом: for i:=1 to n do
if k[i] = key then
begin
search = i; exit;
end; search = 0; exit;
Эффективность последовательного поиска в массиве можно определить как количество производимых сравнений М. Мmin = 1, Mmax =
n. Если данные расположены равновероятно во всех ячейках массива, то Мср (n + 1)/2.
Если элемент не найден в таблице и необходимо произвести вставку, то последние 2 оператора заменяются на
n = n + 1 на Паскале
k(n) = key n:=n+1;
r(n) = rec k[n]:=key;
search = n r[n]:=rec;
return search:=n;
exit;
Если таблица данных задана в виде односвязного списка, то производится последовательный поиск в списке (рис. 51).
Рис. 51
Варианты алгоритмов:
На псевдокоде:
q=nil p=table
while (p <> nil) do if k(p) = key then search = p
return endif
q = p
p = nxt(p) endwhile
s = getnode k(s) = key r(s) = rec nxt(s) = nil
if q = nil then table = s
else nxt(q) = s endif
search = s return
На Паскале:
q:=nil; p:=table;
while (p <> nil) do begin
if p^.k = key then begin
search = p; exit;
end; q := p;
p := p^.nxt; end; New(s); s^.k:=key; s^.r:=rec; s.^nxt:= nil;
if q = nil then table = s
else q.^nxt = s; search:= s;
exit
Достоинством списковой структуры является ускоренный алгоритм удаления или вставки элемента в список, причем время вставки или удаления не зависит от количества элементов, а в массиве каждая вставка или удаление требуют передвижения примерно половины элементов. Эффективность поиска в списке примерно такая же, как и в массиве.
Эффективность последовательного поиска можно увеличить.
Пусть имеется возможность накапливать запросы за день, а ночью их обрабатывать. Когда запросы собраны, происходит их сортировка.
-
Индексно-последовательный поиск.
При таком поиске организуется две таблицы: таблица данных со своими ключами (упорядоченная по возрастанию) и таблица индексов, которая тоже состоит из ключей данных, но эти ключи взяты из основной таблицы через определенный интервал (рис. 52).
Сначала производится последовательный поиск в таблице индексов по заданному аргументу поиска. Как только мы проходим ключ, который оказался меньше заданного, то этим мы устанавливаем нижнюю границу поиска в основной таблице – low, а затем – верхнюю – hi, на которой (kind
> key).
Например, key = 101.
Поиск идет не по всей таблице, а от low до hi.
Рис. 52
Примеры программ:
Псевдокод:
i = 1
while (i <= m) and (kind(i) <= key) do i=i+1
endwhile
if i = 1 then low = 1 else low = pind(i-1) endif
if i = m+1 then hi = n else hi = pind(i)-1 endif
for j=low to hi
if key = k(j) then search=j
return endif next j search=0
return
Паскаль:
i:=1;
while (i <= m) and (kind[i] <= key) do i=i+1;
if i = 1 then low:=1 else low:=pind[i-1]; if i = m+1 then hi:=n else hi:=pind[i]-1; for j:=low to hi do
if key = k[j] then begin
search:=j; exit;
end; search:=0; exit;
-
Эффективность последовательного поиска.
Эффективность любого поиска может оцениваться по количеству сравнений C аргумента поиска с ключами таблицы данных. Чем меньше количество сравнений, тем эффективнее алгоритм поиска.
Эффективность последовательного поиска в массиве:
C = 1 n, C = (n + 1)/2.
Эффективность последовательного поиска в списке – то же самое. Хотя по количеству сравнений поиск в связанном списке имеет ту же эффективность, что и поиск в массиве, организация данных в виде массива и списка имеет свои достоинства и недостатки. Целью поиска является выполнение следующих процедур:
-
Найденную запись считать.
-
При отсутствии записи произвести ее вставку в таблицу.
-
Найденную запись удалить.
Первая процедура (собственно поиск) занимает для них одно время. Вторая и третья процедуры для списочной структуры более эффективна (т. к. у массивов надо сдвигать элементы).
Если k – число передвижений элементов в массиве, то k = (n + 1)/2.
-
-
Эффективность индексно-последовательного поиска.
Ecли считать равновероятным появление всех случаев,то эффективность поиска можно рассчитать следующим образом:
Введем обозначения: m – размер индекса; m = n / p; p – размер шага
Q = (m+1)/2 + (p+1)/2 = (n/p+1)/2 + (p+1)/2 = n/2p+p/2+1
Продифференцируем Q по p и приравняем производную нулю:
dQ/dp=(d/dp) (n/2p+p/2+1)= – n / 2 p2 + 1/2 = 0
Отсюда
p2=n;
n
pопт
Подставив ропт в выражение для Q, получим следующее количество сравнений:
n
Q = +1
n
Порядок эффективности индексно-последовательного поиска O ( )
-
Методы оптимизации поиска.
Всегда можно говорить о некотором значении вероятности поиска того или иного элемента в таблице. Считаем, что в таблице данный элемент существует. Тогда вся таблица поиска может быть представлена как система с дискретными состояниями, а вероятность нахождения там искомого элемента – это вероятность p(i) i – го состояния системы.
n
p(i) 1
i1
Количество сравнений при поиске в таблице, представленной как дискретная система, представляет собой математическое ожидание значения дискретной случайной величины, определяемой вероятностями состояний и номерами состояний системы.
Z=Q=1p(1)+2p(2)+3p(3)+…+np(n)
Желательно, чтобы p(1)p(2) p(3) …p(n).
Это минимизирует количество сравнений, то есть увеличивает эффективность. Так как последовательный поиск начинается с первого элемента, то на это место надо поставить элемент, к которому чаще всего обращаются (с наибольшей вероятностью поиска).
Наиболее часто используются два основных способа автономного переупорядочивания таблиц поиска. Рассмотрим их на примере односвязных списков.
-
Переупорядочивание таблицы поиска путем перестановки найденного элемента в начало списка.
Суть этого метода заключается в том, что элемент списка с ключом, равным заданному, становится первым элементом списка, а все остальные сдвигаются.
Рис. 53
Этот алгоритм применим как для списков, так и для массивов. Однако не рекомендуется применять его для массивов, так как на перестановку элементов массива затрачивается гораздо больше времени, чем на перестановку указателей.
Алгоритм переупорядочивания в начало списка:
Псевдокод:
q=nil p=table
while (p <> nil) do if key = k(p) then
if q = nil then ‘перестановка не нужна’ search = p
return endif
nxt(q) = nxt(p) nxt(p) = table table = p search = p return
endif q = p
p = nxt(p) endwhile search = nil return
Паскаль:
q:=nil; p:=table;
while (p <> nil) do begin
if key = p^.k then begin
if q = nil
then ‘перестановка не нужна’ search := p;
exit; end;
q^.nxt := p^.nxt; p^.nxt := table; table := p;
exit; end;
q := p;
p := p^.nxt; end;
search := nil; exit;
-
Метод транспозиции.
В данном методе найденный элемент переставляется на один элемент к голове списка. И если к этому элементу обращаются часто, то, перемещаясь к голове списка, он скоро окажется на первом месте.
Рис. 54. Перестановка соседних элементов
р – рабочий указатель;
q – вспомогательный указатель, отстает на один шаг от р; s – вспомогательный указатель, отстает на два шага от q.
Алгоритм метода транспозиции:
Псевдокод:
s=nil q=nil p=table
while (p <> nil) do if key = k(p) then
‘ нашли, транспонируем if q = nil then
‘ переставлять не надо search=p
return endif
nxt(q)=nxt(p) nxt(p)=q
if s = nil then table = p else nxt(s)=p
endif search=p return endif endwhile search=nil return
Паскаль:
s:=nil; q:=nil; p:=table;
while (p <> nil) do begin
if key = p^.k then
‘ нашли, транспонируем begin
if q = nil then begin
‘переставлять не на- до search:=p;
exit; end;
q^.nxt:=p^.nxt; p^.nxt:=q;
if s = nil then table := p; else
begin
s^.nxt := p;
end; search:=p; exit;
end; end;
search:=nil; exit
Этот метод удобен при поиске не только в списках, но и в массивах (так как меняются только два стоящих рядом элемента).
-
Дерево оптимального поиска.
Если извлекаемые элементы сформировали некоторое постоянное множество, то может быть выгодным настроить дерево бинарного поиска для большей эффективности последующего поиска.
Рассмотрим деревья бинарного поиска, приведенные на рисунках a и b.Оба дерева содержат три элемента – к1, к2, к3, где к1<к2<к3. Поиск элемента к3 требует двух сравнений для рисунка 55 a), и только одного – для рисунка 55 б).
Число сравнений ключей, которые необходимо сделать для извлечения некоторой записи, равно уровню этой записи в дереве бинарного поиска плюс 1.
Предположим, что:
p1 – вероятность того, что аргумент поиска key = к1; р2 – вероятность того, что аргумент поиска key = к2; р3 – вероятность того, что аргумент поиска key = к3; q0 – вероятность того, что key < к1;
q1 – вероятность того, что к2 > key > к1; q2 – вероятность того, что к3 > key > к2; q3 – вероятность того, что key > к3;
C1 – число сравнений в первом дереве рисунка 55 a);
C2 – число сравнений во втором дереве рисунка 55 б).
Рис. 55
Тогда р1+р2+р3+q0+q1+q2+q3 = 1
Ожидаемое число сравнений в некотором поиске есть сумма произведений вероятности того, что данный аргумент имеет некоторое заданное значение, на число сравнений, необходимых для извлечения этого значения, где сумма берется по всем возможным значениям аргумента поиска. Поэтому
C1 = 2р1+1р2+2р3+2q0+2q1+2q2+2q3 C2 = 2р1+3р2+1р3+2q0+3q1+3q2+1q3
Это ожидаемое число сравнений может быть использовано как некоторая мера того, насколько «хорошо» конкретное дерево бинарного поиска подходит для некоторого данного множества ключей и некоторого заданного множества вероятностей. Так, для вероятностей, приведенных далее слева, дерево из a) является более эффективным, а для вероятностей, приведенных справа, дерево из б) является более эффективным:
P1 = 0.1 P1 = 0.1
P2 = 0.3 P2 = 0.1
P3 = 0.1 P3 = 0.3
q0 = 0.1
q0 = 0.1
q1 = 0.2
q1 = 0.1
q2 = 0.1
q2 = 0.1
q3 = 0.1
q3 = 0.2
C1 = 1.7
C1 = 1.9
C2 = 2.4
C2 = 1.8
Дерево бинарного поиска, которое минимизирует ожидаемое число сравнений некоторого заданного множества ключей и вероятностей, называется оптимальным. Хотя алгоритм создания дерева может быть очень трудоемким, дерево, которое он создает, будет работать эффективно во всех последующих поисках. К сожалению, однако, заранее вероятности аргументов поиска редко известны.
-
-
Бинарный поиск (метод деления пополам).
Будем предполагать, что имеем упорядоченный по возрастанию массив чисел. Основная идея – выбрать случайно некоторый элемент AM и сравнить его с аргументом поиска Х. Если AM=Х, то поиск закончен; если AM <X, то мы заключаем, что все элементы с индексами, меньшими или равными М, можно исключить из дальнейшего поиска. Аналогично, если AM >X.
Выбор М совершенно произволен в том смысле, что корректность алгоритма от него не зависит. Однако на его эффективность выбор влияет. Ясно, что наша задача- исключить как можно больше элементов из дальнейшего поиска. Оптимальным решением будет выбор среднего элемента, т.е. середины массива.
Рассмотрим пример, представленный на рис. 5.7. Допустим нам необходимо найти элемент с ключом 52. Первым сравниваемым элементом будет 49. Так как 49<52, то ищем следующую середину среди элементов, расположенных выше 49. Это число 86. 86>52, поэтому теперь ищем 52 среди элементов, расположенных ниже 86, но выше 49. На следующем шаге обнаруживаем, что очередное значение середины равно
-
Мы нашли элемент в массиве с заданным ключом.
Рис. 56
Программы на псевдокоде и Паскале:
Low = 1 hi = n
while (low <= hi) do mid = (low + hi) div 2 if key = k(mid) then search = mid
return endif
if key < k(mid) then hi = mid – 1
else low = mid + 1 endif
endwhile search = 0 return
low := 1; hi := n;
while (low <= hi) do begin
mid := (low + hi) div 2; if key = k[mid] then begin
search := mid; exit;
end;
if key < k[mid] then hi := mid – 1
else low := mid + 1; end;
search := 0; exit
При key = 101 запись будет найдена за три сравнения (в последовательном поиске понадобилось бы семь сравнений).
Если С – количество сравнений, а n – число элементов в таблице, то
С = log2n.
Например, n = 1024.
При последовательном поиске С = 512, а при бинарном С = 10.
Можно совместить бинарный и индексно-последовательный поиск (при больших объемах данных), учитывая, что последний также используется при отсортированном массиве.
-
Поиск по бинарному дереву.
Назначение его в том, чтобы по заданному ключу осуществить поиск узла дерева. Длительность операции зависит от структуры дерева. Действительно, дерево может быть вырождено в однонаправленный список, как правое на рис. 57.
Рис. 57. Бинарные деревья
В этом случае время поиска будет такое же, как и в однонаправленном списке, т.е. придется перебирать N/2 элементов.
Наибольшего эффекта использования дерева достигается в том случае, когда дерево сбалансировано.В этом случае для поиска придотся перебрать не больше log2N элементов.
Строго сбалансированное дерево – это дерево, в котором каждый узел имеет левое и правое поддеревья, отличающиеся по уровню не более, чем на единицу.
Поиск элемента в бинарном дереве называется бинарным поиском по дереву.
Такое дерево называют деревом бинарного поиска.
Суть поиска заключается в следующем. Анализируем вершину очередного поддерева. Если ключ меньше информационного поля вершины, то анализируем левое поддерево, больше – правое.
Пусть задан аргумент key.
p = tree
whlie p <> nil do if key = k(p) then search = p
return endif
if key < k(p) then p = left(p)
else
p = right(p) endif endwhile
search = nil return
p := tree;
whlie p <> nil do begin
if key = p^.k then begin
search := p; exit;
end;
if key < p^.k then p := p^.left
else
p := p^.right; end;
search := nil;
-
Поиск со вставкой (с включением).
Для вставки элемента в дерево, сначало нужно осуществить поиск в дереве по заданному ключу. Если такой ключ имеется, то программа завершается, если нет, то происходит вставка.
Для включения новой записи в дерево, прежде всего нужно найти тот узел, к которому можно присоединить новый элемент. Алгоритм поиска нужного узла тот же самый, что и при поиске узла с заданным ключом. Однако непосредственно использовать процедуру поиска нельзя, потому что по ее окончании не фиксирует тот узел, из которого была выбрана ссылка NIL (search = nil).
Модифицируем описание процедуры поиска так, чтобы в качестве ее побочного эффекта фиксировалась ссылка на узел, в котором был найден заданный ключ (в случае успешного поиска), или ссылка на узел, после обработки которого поиск прекращается (в случае неуспешного поиска).
Псевдокод:
P = tree Q = nil
Whlie p <> nil do q = p
if key = k(p) then search = p return
endif
if key < k(p) then p = left(p)
else
p = right(p) endif endwhile
v = maketree(key, rec) if q = nil then
tree = v else
if key < k(q) then left(q) = v
else
right(q) = v endif
endif
search = v return
Паскаль:
p := tree; q := nil;
whlie p <> nil do begin
q := p;
if key = p^.k then begin
search := p; exit;
end;
if key < p^.k then p := p^.left
else
p := p^.right; end;
v := maketree(key, rec) if q=nil then
tree:=v else
if key < q^.k then q^.left := v
else
q^.right := v; search := v;
-
Поиск с удалением.
-
Удаление узла не должно нарушить упорядоченности дерева.
Возможны три варианта:
-
Найденный узел является листом. Тогда он просто удаляется и
все.
-
Найденный узел имеет только одного сына. Тогда сын
перемещается на место отца.
-
У удаляемого узла два сына. В этом случае нужно найти подходящее звено поддерева, которое можно было бы вставить на место удаляемого. Такое звено всегда существует:
-
это либо самый правый элемент левого поддерева (для достижения этого звена необходимо перейти в следующую вершину по левой ветви, а затем переходить в очередные вершины только по правой ветви до тех пор, пока очередная ссылка не будет равна NIL;
-
либо самый левый элемент правого поддерева (для достижения этого звена необходимо перейти в следующую вершину по правой ветви, а затем переходить в очередные вершины только по левой ветви до тех пор, пока очередная ссылка не будет равна NIL.
Предшественником удаляемого узла называют самый правый узел левого поддерева (для 12 – 11). Преемником – самый левый узел правого поддерева (для 12 – 13).
Будем разрабатывать алгоритм для преемника (рис.58). p – рабочий указатель;
q – отстает от р на один шаг;
v – указывает на приемника удаляемого узла; t – отстает от v на один шаг;
s – на один шаг впереди v (указывает на левого сына или пустое место).
Рис. 58. Удаление узлов дерева
На узел 13 в конечном итоге должен указывать v, а указатель s – на пустое место (как показано на рис. 58).
Псевдокод:
q = nil p = tree
while (p <> nil) and (k(p) <> key) do q = p
if key < k(p) then p = left(p)
else
p = right(p) endif endwhile
if p = nil then ‘Ключ не найден’ return
endif
if left(p) = nil then v = right(p)
else if right(p) = nil
then v = left(p) else
‘У nod(p) – два сына’
‘Введем два указателя (t отстает от v на 1 ‘шаг, s – опережает)
t = p
v = right(p) s = left(v)
while s <> nil do t = v
v = s
s = left(v) endwhile
if t <> p then
‘v не является сыном p’ left(t) = right(v)
right(v) = right(p) endif
left(v) = left(p) endif
endif
if q = nil then ‘p – корень’
tree = v else if p = left(q)
then left(q) = v else right(q) = v endif
endif freenode(p) return
Паскаль:
q := nil; p := tree;
while (p <> nil) and (p^.k <> key) do begin
q := p;
if key < p^.k then p := p^.left
else
p := p^.right; end;
if p = nil then
WriteLn(‘Ключ не найден’);
exit;
end;
if p^.left = nil then v := p^.right
else
if p^.right = nil then v := p^.left
else
begin
{Введем два указателя (t отстает от v на 1 шаг, s – опережает)}
t := p;
v := p^.right; s := v^.left;
while s <> nil do begin
t := v;
v := s;
s := v^.left; end;
if t <> p then begin
WriteLn(‘v не является сыном p’); t^.left := v^.right;
v^.right := p^.right; end;
v^.left := p^.left; end;
end;
if p = q^.left then q^.left := v
else
q^.right := v; end;
dispose(p); end;
Вопрос 6. Сортировка.
При обработке данных важно знать информационное поле данных и размещение их в машине.
Различают внутреннюю и внешнюю сортировку:
-
внутренняя сортировка – сортировка в оперативной памяти;
-
внешняя сортировка – сортировка во внешней памяти.
Сортировка – это расположение данных в памяти в регулярном виде по их ключам. Регулярность рассматривают как возрастание (убывание) значения ключа от начала к концу в массиве.
Рис. 59. Сортировка
Если сортируемые записи занимают большой объем памяти, то их перемещение требует больших затрат. Для того, чтобы их уменьшить, сортировку производят в таблице адресов ключей, делают перестановку указателей, т.е. сам массив не перемещается. Это метод сортировки таблицы адресов.
При сортировке могут встретиться одинаковые ключи. В этом случае при сортировке желательно расположить после сортировки одинаковые ключи в том же порядке, что и в исходном файле. Это – устойчивая сортировка.
Эффективность сортировки можно рассматривать с нескольких критериев:
-
время, затрачиваемое на сортировку;
-
объем оперативной памяти, требуемой для сортировки;
-
время, затраченное программистом на написание программы.
Выделяем первый критерий, поскольку будем рассматривать только методы сортировки «на том же месте», то есть не резервируя для процесса сортировки дополнительную память. Эквивалентом затраченного на сортировку времени можно считать количество сравнений при выполнении сортировки и количество перемещений.
Порядок числа сравнения при сортировке лежит в пределах от О (n log n) до О (n2); О (n) – идеальный и недостижимый случай.
Различают следующие методы сортировки:
-
строгие (прямые) методы;
-
улучшенные методы.
Строгие методы:
-
метод прямого включения;
-
метод прямого выбора;
-
метод прямого обмена.
Эффективность этих трех методов примерно одинакова.
-
Сортировка методом прямого включения.
Такой метод широко используется при игре в карты. Элементы мысленно делятся на уже готовую последовательность a1,…,ai-1 и исходную последовательность. При каждом шаге, начиная с i = 2 и увеличивая i каждый раз на единицу, из исхожной последовательности извлекается i-й элемент и перекладывается в готовую последовательность, при этом он вставляется на нужное место.На рис. 60 показан в качестве примера процесс сортировки с помощью включения шести случайно выбранных чисел. Алгоритм этой сортировки таков:
for i = 2 to n x = a(i)
находим место среди а(1)…а(i) для включения х next i
Рис. 60. Сортировка методом прямого включения
Для сортировки методом прямого включения пользуются следующими приемами:
Псевдокод:
Без барьера:
for i = 2 to n x = a(i)
for j = i – 1 downto 1 if x < a(j )
then a( j + 1) = a(j ) else go to L
endif next j
L: a( j + 1) = x next i
return
С барьером:
for i = 2 to n x = a(i)
a(0) = x {a(0) – барьер} j = i – 1
while x < a(j ) do a( j +1) = a(j )
j = j – 1 endwhile
a( j +1) = x next i
return
Паскаль:
Без барьера:
for i:= 2 to n do begin
x:= a(i);
for j:= i – 1downto 1 do if x < a(j ) then
a(j +1):= a(j ) else goto 1; end;
end;
1: a(j + 1):= x;
end; end;
С барьером:
for i := 2 to n do begin
x:= a(i);
a(0):= x; {a(0) – барьер} j:= i – 1;
while x < a(j ) do begin
a(j +1):= a(j ); j:=j – 1;
end;
a(j +1):= x; end
Эффективность алгоритма.
Число сравнений ключей Ci при i- м просеивании самое большее равно i-1, самое меньшее – 1; если предположить, что все перестановки из N ключей равновероятны, то среднее число сравнений = i/2. Число же пересылок Mi=Ci+3 (включая барьер). Минимальные оценки встречаются в случае уже упорядоченной исходной последовательности элементов, наихудшие же оценки – когда они первоначально расположены в обратном порядке. В некотором смысле сортировка с помощью включения демонстрирует истинно естественное поведение. Ясно, что приведенный алгоритм описывает процесс устойчивой сортировки: порядок элементов с равными ключами при нем остается неизменным.
Количество сравнений в худшем случае, когда массив отсортирован противоположным образом, Сmax = n(n – 1)/2, т. е. – О (n2). Количество перестановок Mmax = Cmax + 3(n-1), т.е. – О (n2). Если же массив уже отсортирован, то число сравнений и перестановок минимально: Cmin = n- 1; Mmin = =3(n-1).
-
Сортировка методом прямого выбора.
Этот прием основан на следующих принципах:
-
Выбирается элемент с наименьшим ключом.
-
Он меняется местами с первым элементом a 1.
-
Затем этот процесс повторяется с оставшимися n-1 элементами, n-2 элементами и т.д. до тех пор, пока не останется один, самый
«большой» элемент.
Алгоритм формулируется так:
|
for i = 1 to n – 1 x = a(i) k = i for j = i + 1 to n if a(j) < x then k = j x = a(k) endif next j a(k) = a(i) a(i) = x next i return |
for i := 1 to n – 1 do begin x := a[i]; k := i; for j := i + 1 to n do if a[j] < x then begin k := j; x := a[k]; end; a[k] := a[i]; a[i] := x; end; |
Эффективность алгоритма:
Число сравнений ключей C, очевидно, не зависит от начального порядка ключей. Можно сказать, что в этом смысле поведение этого метода менее естественно, чем поведение прямого включения. Для C при любом расположении ключей имеем:
C = n(n-1)/2
Порядок числа сравнений, таким образом, О(n2).
Число перестановок минимально Мmin = 3(n – 1) в случае изначально упорядоченных ключей и максимально, Мmax = 3(n – 1) + С, т.е. порядок О(n2), если первоначально ключи располагались в обратном порядке.
В худшем случае сортировка прямым выбором дает порядок n2, как для числа сравнений, так и для числа перемещений.
-
Сортировка с помощью прямого обмена (пузырьковая сортировка).
Классификация методов сортировки редко бывает осмысленной. Оба разбиравшихся до этого метода можно тоже рассматривать как
«обменные» сортировки. В данном же, однако, разделе описан метод, где обмен местами двух элементов представляет собой характернейшую особенность процесса. Изложенный ниже алгоритм прямого обмена основывается на сравнении и смене мест для пары соседних элементов и продолжении этого процесса до тех пор, пока не будут упорядочены все элементы.
Как и в упоминавшемся методе прямого выбора, мы повторяем проходы по массиву, сдвигая каждый раз наименьший элемент оставшейся последовательности к левому концу массива. Если мы будем рассматривать массивы как вертикальные, а не горизонтальные построения, то элементы можно интерпретировать как пузырьки в чане с водой, причем вес каждого соответствует его ключу. В этом случае при каждом проходе один пузырек как бы поднимается до уровня, соответствующего его весу (см. рис. 61).
Такой метод широко известен под именем «пузырьковая сортировка». В своем простейшем виде он представлен ниже.
Рис. 61
Программы на псевдокоде и Паскале:
for i = 2 to n
for j = n to i step -1 if a(j) < a(j – 1) then x = a(j – 1)
a(j – 1) = a(j) a(j) = x
endif next j
next i return
for i := 2 to n do
for j := n downto i do if a[j] < a[j – 1]then begin
x := a[j – 1];
a[j – 1] := a[j]; a[j] := x;
end; end;
end;
В нашем случае получился один проход “вхолостую”. Чтобы лишний раз не переставлять элементы, можно ввести флажок fl, который остается в значении false, если при очередном проходе не будет произведено ни одного обмена. На нижеприведенном алгоритме добавления отмечены курсивом.
fl = true
for i = 2 to n
if fl = false then return endif
fl = false
for j = n to i step -1 if a(j) < a(j – 1) then
fl = true x = a(j – 1)
a(j – 1) = a(j) a(j) = x
endif
next j
next i return
Улучшением пузырькового метода является шейкерная сортировка, где после каждого прохода меняют направление во внутреннем цикле.
Эффективность алгоритма:
Число сравнений Cmax = n(n-1)/2,О(n2).
Число перемещений Мmax=3Cmax=3n(n-1)/2, О(n2).
Если массив уже отсортирован и применяется алгоритм с флажком, то достаточно всего одного прохода, и тогда получаем минимальное число сравнений
Cmin = n – 1, О(n),
а перемещения вообще отсутствуют.
Сравнительный анализ прямых сортировок показывает, что обменная «сортировка» в классическом виде представляет собой нечто среднее между сортировками с помощью включений и с помощью выбора. Если же в нее внесены приведенные выше усовершенствования, то для достаточно упорядоченных массивов пузырьковая сортировка даже имеет преимущество.
-
Улучшенные методы сортировки.
-
Быстрая сортировка (Quick Sort).
Относится к методам обменной сортировки. В основе лежит методика разделения ключей по отношению к выбранному.
Рис. 62. Быстрая сортировка
Слева от 6 располагают все ключи с меньшими, а справа – с большими или равными 6 (рис. 62).
Sub Sort (L, R) i = L
j = R
x = a((L + R) div 2) repeat
while a(i) < x do i = i + 1 endwhile
while a(j) > x do j = j – 1 endwhile
if i <= j then y = a(i) a(i) = a(j) a(j) = y
i = i + 1 j = j – 1 endif
until i > j
if L < j then sort (L, j) endif
if i < R then sort (i, R) endif
return
sub QuickSort sort (1, n)
return
procedure Sort (L, R: integer); begin
i := L;
j := r;
x := a[(L + r) div 2]; repeat
while a[i] < x do i := i + 1;
while a[j] > x do j := j – 1;
if i <= j then begin
y := a[i]; a[i] := a[j]; a[j] := y;
i := i + 1;
j := j – 1 end;
until i > j;
if L < j then sort (L, j); if i < r then sort (i, r); end;
procedure QuickSort; begin
sort (1, n); end;
Эффективность алгоритма:
О(n log n) – самый эффективный метод.
-
Сортировка Шелла (сортировка с уменьшающимся шагом).
В 1959 году Д. Шеллом было предложено усовершенствование сортировки с помощью метода прямого включения. Работа его представлена на рис. 63:
Рис. 63. Сортировка Шелла
Сначала отдельно группируются и сортируются элементы, отстоящие друг от друга на расстоянии 4. Такой процесс называется четверной сортировкой. После первого прохода элементы перегруппировываются – теперь каждый элемент группы отстоит от другого на 2 позиции – и вновь сортируются. Это называется двойной сортировкой. И, наконец, на третьем проходе идет обычная или одиночная сортировка.
На первый взгляд можно засомневаться: если необходимо несколько процессов сортировки, причем в каждый включаются все элементы, то не добавят ли они больше работы, чем сэкономят? Однако, на каждом этапе либо сортируется относительно мало элементов, либо элементы уже довольно хорошо упорядочены и требуют сравнительно немного перестановок.
Ясно, что такой метод в результате дает упорядоченный массив, и, конечно, сразу же видно, что каждый проход от предыдущих только выигрывает; также очевидно, что расстояния в группах можно уменьшать по разному, лишь бы последнее было единичным, ведь в самом плохом случае последний проход и сделает всю работу.
Приводимый алгоритм основан на методе прямой вставки без барьера и не ориентирована на некую определенную последовательность расстояний, хотя в нем для конкретности заданы шаги 5, 3 и 1.
При использовании метода барьера каждая из сортировок нуждается в постановке своего собственного барьера, и программу для определения его местонахождения необходимо делать насколько возможно простой. Поэтому приходится расширять массив до [-h1..N].
h[1..t] – массив размеров шагов; a[1..n] – сортируемый массив;
k – шаг сортировки;
x – значение вставляемого элемента.
|
Subroutine ShellSort Псевдокод: const t = 3 h(1) = 5 h(2) = 3 h(3) = 1 for m = 1 to t k = h(m) for i = k + 1 to n x = a(i) for j = i – k to 1 step -k if x < a(j) then a( j+k) = a(j) else goto L endif next j L: a(j+k) = x next i next m return |
Паскаль: const t = 3; h(1) = 5; h(2) = 3; h(3) = 1; var h: array [1..t] of integer; a: array [1..n] of integer; k, x, m, t, i, j: integer; begin for m = 1 to t do begin k:= h(m); for i = k + 1 to n do begin x:= a(i); for j = i-k downto k do begin if x < a(j ) then a(j+k):= a(j); else goto 1; end ; end; end; 1: a(j+1) = x ; end; end . |
Не доказано, какие расстояния дают наилучший результат, но они не должны быть множителями один другого.
Д. Кнут предлагает такую последовательность шагов (в обратном порядке): 1, 3, 7, 15, 31, … То есть: h m-1 = h m + 1, t = log2n – 1. При такой организации алгоритма его эффективность имеет порядок O (n1.2)
Вопрос 7. Преобразование ключей (расстановка).
Метод расстановок (хеширования) направлен на быстрое решение задачи о местоположении элемента в структуре данных. В методе расстановок данные организованы как обычный массив. Поэтому Н – отображение, преобразующее ключи в индексы массива, отсюда и появилось название «преобразование ключей», обычно даваемое этому методу. Следует заметить, что нет никакой нужды обращаться к каким- либо процедурам динамического размещения, ведь массив — это один из основных, статических объектов. Метод преобразования ключей часто используется для таких задач, где можно с успехом воспользоваться и деревьями.
Основная трудность, связанная с преобразованием ключей, заключается в том, что множество возможных значений значительно шире множества допустимых адресов памяти (индексов массива). Возьмем в качестве примера имена, включающие до 16 букв и представляющие собой ключи, идентифицирующие отдельные индивиды из множества в тысячу персон. Следовательно, мы имеем дело с 2616 возможными ключами, которые нужно отобразить в 103 возможных индексов. Поэтому функция Н будет функцией класса «много значений в одно значение». Если дан некоторый ключ k, то первый шаг операции поиска — вычисление связанного с ним индекса h = H(k), а второй (совершенно необходимый) — проверка, действительно ли h идентифицирует в массиве (таблице) Т элемент с ключом k.
-
Выбор функции преобразования.
Само собой разумеется, что любая хорошая функция преобразования должна как можно равномернее распределять ключи по всему диапазону значений индекса. Если это требование удовлетворяется, то других ограничений уже нет, и даже хорошо, если преобразование будет выглядеть как совершенно случайное. Такая особенность объясняет несколько ненаучное название этого метода — «перемалывание» (хеширование), т. е. дробление аргумента, превращение его в какое-то «месиво». Функция же Н будет называться «функцией расстановки». Ясно, что Н должно вычисляться достаточно эффективно, т. е. состоять из очень небольшого числа основных арифметических операций.
Представим себе, что есть функция преобразования ORD(k), обозначающая порядковый номер ключа k в множестве всех возможных ключей. Кроме того, будем считать, что индекс массива i лежит в диапазоне 0… N — 1, где N — размер массива. В этом случае ясно, что нужно выбрать следующую функцию:
H(k) = ORD(k) MOD N
Для нее характерно равномерное отображение значений ключа на весь диапазон изменения индексов, поэтому ее кладут в основу большинства преобразований ключей. Кроме того, при N, равном степени двух, эта функция эффективно вычисляется. Однако если ключ представляет собой последовательность букв, то именно от такой функции и следует отказаться. Дело в том, что в этом случае допущение о равновероятности всех ключей ошибочно. В результате слова, отличающиеся только несколькими символами, с большой вероятностью будут отображаться в один и тот же индекс, что приведет к очень неравномерному распределению. Поэтому на практике рекомендуется в качестве N брать простое число. Следствием такого выбора будет необходимость использования полной операции деления, которую уже нельзя заменить выделением нескольких двоичных цифр.
-
Алгоритм.
Если обнаруживается, что строка таблицы, соответствующая заданному ключу, не содержит желаемого элемента, то, значит, произошел конфликт, т. е. два элемента имеют такие ключи, которые отображаются в один и тот же индекс. В этой ситуации нужна вторая попытка с индексом, вполне определенным образом получаемым из того же заданного ключа. Существует несколько методов формирования вторичного индекса. Очевидный прием — связывать вместе все строки с идентичным первичным индексом H(k). Превращая их в связанный список. Такой прием называется прямым связыванием (direct chaining). Элементы получающегося списка могут либо помещаться в основную таблицу, либо нет; в этом случае память, где они размещаются, обычно называется областью переполнения. Недостаток такого приема в том, что нужно следить за такими вторичными списками и в каждой строке отводить место для ссылки (или индекса) на соответствующий список конфликтующих элементов.
Другой прием разрешения конфликтов состоит в том, что мы совсем отказываемся от ссылок и вместо этого просматриваем другие строки той же таблицы — до тех пор, пока не обнаружим желаемый элемент или же пустую строку. В последнем случае мы считаем, что указанного ключа в таблице нет. Такой прием называется открытой адресацией. Естественно, что во второй попытке последовательность индексов должна быть всегда одной и той же для любого заданного ключа. В этом случае алгоритм просмотра строится по такой схеме:
h = H(k) i = 0 repeat
if T(h) = k
then элемент найден
else if T(h) = free
then элемента в таблице нет
else {конфликт}
i := i + 1
h := H(k) + G(i)
endif endif
until либо найден, либо нет в таблице (либо она полна)
Предлагались самые разные функции G(i) для разрешения конфликтов. Приведенный в работе Морриса (1968) обзор стимулировал активную деятельность в этом направлении. Самый простой прием — посмотреть следующую строку таблицы (будем считать ее круговой), и так до тех пор, пока либо будет найден элемент с указанным ключом, либо встретится пустая строка. Следовательно, в этом случае G(i)==i, а индексы hi, употребляемые при последующих попытках, таковы:
h0:= H(k)
hi:= (hi + i) MOD N, i = 1 … N – 1
Такой прием называется линейными пробами, его недостаток заключается в том, что строки имеют тенденцию группироваться вокруг первичных ключей (т. е. ключей, для которых при включении конфликта не возникало). Конечно, хотелось бы выбрать такую функцию G, которая вновь равномерно рассеивала бы ключи по оставшимся строкам. Однако на практике это приводит к слишком большим затратам, потому предпочтительнее некоторые компромиссные методы; будучи достаточно простыми с точки зрения вычислений, они все же лучше линейной функции. Один из них — использование квадратичной функции, в этом случае последовательность пробуемых индексов такова:
h0:= H(k)
hi:= (hi + i2) MOD N, i > 0
Если воспользоваться рекуррентными соотношениями для hi = i2 и di = 2i + l при h0 = 0 и d0 = l, то при вычислении очередного индекса можно обойтись без операции возведения в квадрат.
hi+1 = hi + di
di+1 = di + 2 (i > 0)
Такой прием называется квадратичными пробами, существенно, что он позволяет избежать группирования, присущего линейным пробам, не приводя практически к дополнительным вычислениям. Небольшой же его недостаток заключается в том, что при поиске пробуются не все строки таблицы, т. е. при включении элемента может не найтись свободного места, хотя на самом деле оно есть. Если размер N — простое число, то при квадратичных пробах просматривается по крайней мере половина таблицы. Такое утверждение можно вывести из следующих рассуждений. Если i-я и j-я пробы приводят к одной и той же строке таблицы, то справедливо равенство
i2 MOD N = j2 MOD N
или
(i2 – j2) = 0 (MOD N).
Разлагая разность на два множителя, получаем
(i + j)(i – j) = 0 (MOD N).
Поскольку i j, то либо i, либо j должны быть больше N/2, чтобы было справедливо равенство i + j = cN, где с — некоторое целое число. На практике упомянутый недостаток не столь существен, так как N/2 вторичных попыток при разрешении конфликтов встречаются очень редко, главным образом в тех случаях, когда таблица почти заполнена.